Археологические и музейные работы в эпоху развитого нетсталкинга
Уверен, вместе со многими из вас я подписан на замечательный канал @netstalking_narod посвященный архивации контента крупнейшей в рунете агломерации статических сайтов - сервиса Народ.ру и слитых с ним, в свое время, сайтов немаленького хостинга Ucoz.ru. Выражаю уважение и кланяюсь до земли создателю канала. Простая и очевидная, казалось бы, идея, но бот постоянно приносит интересные и просто забавные находки.
Дух этого канала постоянно озарял меня во время работы над этими строками. С одного занятного сообщения на “народном” канале я и начну.
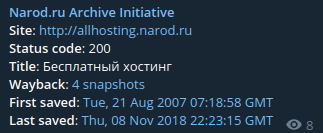
Архиватор Народа часто выгребает мелкую и наивную интернет-комерцию 00х. Всевозможные вырвиглазные сайты “веб-студий”, СЕО, раскрутка, продвижение, ТИЦ, рейтинг без регистрации и смс. Но предложения о хостинге, которое само по себе хостится на бесплатной платформе я видел впервые. Заинтересовавшись, кликаю и перехожу. Симпатичный, светлый и абсолютно безликий сайт. По всей видимости, сгенерирован одним из десятков приложух времен бума доткомов. Логотип смахивает на лого какого-то российского телеканала и отлично выражает эстетику тех времен. Быстрый поиск по картинке приводит на сайты с варезом - оказывается такой же кубик красуется на логотипе какого-то XP-Utilities - программы для антигуманной настройки внешнего вида окон и рабочего стола - тоже Zeitgeist. Еще находится какой-то “ТД Екатерина” с таким же кубом на банере.
Прямо универсальный логотип веба середины двухтысячных, когда порог вхождения в интернет уже немного снизился и для заведения собственного сайта с полезным софтом или стратегиями в популярных онлайн игрушках уже не надо было ботанить HTML и вручную его писать в notepad.exe. Время, когда молодые и незаангажированные дорвались до генераторов сайтов, ворованых стоков и жаждали покорять веб, создавая свои порталы.
Заглядываем в <head>:
<title>Бесплатный хостинг</title>
<meta name="author" content="Serega">
<meta name="generator" content="Web Page Maker V2">
<meta name="description" content="бесплатный хостинг">
<meta name="keywords" content="бесплатный хостинг, хостинг, создание сайтов">
<meta name="document-state" content="static">
<meta name="robots" content="all">
<meta name="cache-control" content="public">
<meta name="content-language" content="Русский">
<meta name="author" content="Serega"> - интернет, который мы потеряли. Перехожу на webpage-maker.com/gallery.html - небольшой каталог ссылок, некоторые сайты даже грузятся. Кое-где уже крутится вордпресс, но по нескольким линкам я нашел тот же meta generator - забавно, но не более. Возвращаемся к виновнику торжества.
Копошимся в статике былого
Конечно же, я поспешил попробовать все ссылки в списке “Бесплатный хостинг”.
-
www.narod.ru - жив,
-
www.boom.ru - теперь тут стриминг сервис VK и Одноклассников. В 2000м Boom.ru был отдельным порталом и хостингом. Он был разработан компанией NetBridge (прото-mail.ru group) в пику Народу от CompTek (прото-Яндекс). Позже, примерно в 2003-2004, он стал называться “Хостинг@mail.ru” или “Мой сайт mail.ru”. В конце концов сервис закрылся.

В копилку памяти - куда пропали сайты с сервиса? Как много из них лежит в веб архиве? Все это еще ждет своих исследователей…
-
www.newmail.ru - домен все еще кем-то куплен, но не используется. До того как стать частью qip.ru в январе 2010, проект успел побывать Почтой.ру. Позже qip переехал на почту яндекса. Я находил упоминания, что во времена qip’а почта на newmail продолжала ходить. Проверим?
dig @1.1.1.1 newmail.ru MXДа, действительно, яндекс
; <<>> DiG 9.11.5-P4-1-Debian <<>> @1.1.1.1 newmail.ru MX ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9271 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1452 ;; QUESTION SECTION: ;newmail.ru. IN MX ;; ANSWER SECTION: newmail.ru. 60 IN MX 10 mx.yandex.net. ;; Query time: 70 msec ;; SERVER: 1.1.1.1#53(1.1.1.1) ;; WHEN: Thu May 09 16:37:35 EEST 2019 ;; MSG SIZE rcvd: 68 -
www.chat.ru - домен на продажу. Сервис “Ваша страница” активен, но каталога нет. Это тоже уходит в копилку, на будущее.
-
www.by.ru - домен выставлен на продажу. Веб-архив находит хостинг в 2011. Где оно сейчас - не понятно.
-
www.tut.by - кажется, 2001 год был незамеченым бумом хостинг-площадок. Видимо в воздухе уже витало ощущение того, что контент должен генерировать пользователь. Нашлась новость за 2001:
Теперь у пользователей Байнета появилась возможность бесплатно завести свой личный web-сайт с “белорусским” адресом вида имя_пользователя.at.tut.by, где имя_пользователя совпадает с именем его почтового ящика на TUT.BY
-
www.sitecity.ru - Сервис жив. Копирайт внизу страницы указывает на последний год обновления - 2016. Какая удача для ленивца, вроде меня. Слева сразу привлекает внимание ссылка “Каталог”. Как говорит описание - “полный список сайтов SiteCity.RU (исключая сайты “для взрослых” и закрытые паролем)”. Интересно, это можно поковырять прямо сейчас.
-
www.envy.nu - выглядит, на удивление, живым. Дизайн все тот же, только внизу вездесущая реклама казино. Где искать сайты неясно. Отходит в копилку к другим живым и полуживым сервисам.
Sitecity
Описание, не гнушаясь капслока, сообщает нам, что это некий аналог современных wix и tilda:
“Что это такое? Куда я попал?”. Ответ прост. Вы находитесь на сервере SiteCity.Ru. Здесь делают сайты. Бесплатно, быстро, удобно. С помощью наших шаблонов. Примеры сайтов смотрите в каталоге или в специально сделанном примере сайта, который можно сделать по нашим шаблонам. Конечно, во многом они похожи друг на друга, и, как правило, не блещут изощрённостью внешних форм, но так ли это важно? Ведь главное в сайте - это информация, а от дизайна требуется, чтобы эта информация удобно воспринималась (не более!). Получить уже готовый сайт через неделю - сложный процесс требующий опыт и знания, но результат будет отличный! Однако дорога к профессионализму - долгая и трудная (и далеко не всегда нужная), да и так ли важно становиться профессионалом в дизайне, изучать HTML, учиться верстать - и все это только для того, чтобы сделать вашу информацию доступной миллионам пользователей сети? Ответ однозначен - НЕТ!
Сайт веб-студии создателей этого чудесного ресурса уже не доступен, смотрим в архив - большую часть времени на www.asperito.ru висит “рыба” Lorem ipsum. Сайт в рабочем состоянии в 2015.
Посмотрим что в “Новостях Сервера”. Новости постились без вычитывания, очевидно, что первое слово - “Нам”:
26.10.2002
На 3 года. Ровно столько времени прошло с тех пор, как была сделана первая страничка на нашем сервере (тогда ещё он назывался генератор домашних страниц и находился по адресу http://www.artnet.ru/generator )
Посмотрим, что оно было?
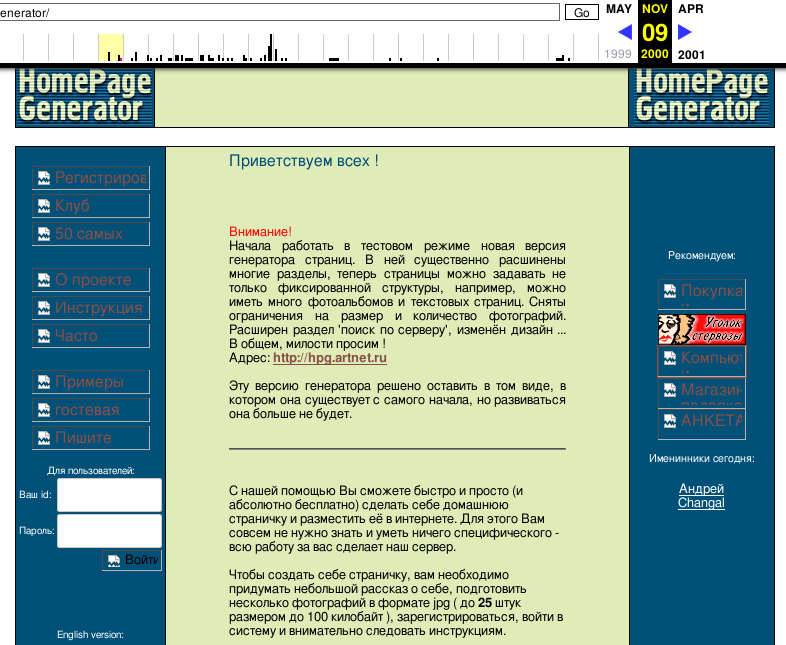
Жаль, каталог “ТОП50” не доступен даже в архиве. Ну ладно, довольно ворошить былое, вернемся к современной версии Sitecity.
Каталог
Разумеется, каталог сайтов разбит на буквено-циферные разделы и имеет пагинацию для каждого индекса. Заглядываем в верстку:
<div align="left">
[A]
[<a href="userlist.phtml?alpha=b">B</a>]
[<a href="userlist.phtml?alpha=c">C</a>]
[<a href="userlist.phtml?alpha=d">D</a>]
...
[<a href="userlist.phtml?alpha=8">8</a>]
[<a href="userlist.phtml?alpha=9">9</a>]
[<a href="userlist.phtml?alpha=0">0</a>]
</div>
Пагинация выглядит где-то так же. Все это находится внутри таблицы внутри таблицы. Классика. Но где наша не пропадала. Запускаю ipython и пытаюсь быстро получить индексы.
Что нам может понадобиться? Задача видится такой - запросить главную страницу каталога, распарсить ссылки на все буквено-циферные указатели. В каждом из них распарсить ссылки на пагинацию, запросить страницы каталога и выудить из таблицы ссылку на страницу, время ее создания и обновления. Все это сложить в какую-нибудь простенькую БД и потом покрутить-посмотреть что там насобиралось. Набор инструментов видится таким (рецепт, разумеется, усредненный, вариаций масса):
from lxml import html
import requests
import sqlite3 as sqlite
import pandas as pd
Для начала соберем все ссылки с заголовками страниц в БД. Подойдет sqlite, потому что это черновой вариант. Конечно, воображене сразу рисует роботов-пауков, Apache Solr и архивирование всего сервиса, но задачи надо решать порционно. В данный момент я хочу получить что-то более удобное, чем HTML-страницы. С базой будет работать уже проще. Пишем пару функций. Я специально не стал заморачиваться созданием класса или генераторов/итераторов. Рефакторинга минимум, потому что это скрипт - его задача отработать единожды, наполнив базу.
Почти 20 лет назад из книги “XML для профессионалов” Дидье Мартина (да, да, у меня была огромная бумажная книга по XML) я узнал про XPath/XQuery. Помню, впечатлившись, написал гостевуху на XML, со своей XSD и логикой на XPath/XQuery. С тех пор я испытываю щенячую радость, если выпадает шанс воспользоваться этими языками, эдакое “спящее знание” внутри моей головы. Поскольку верстка у Sitecity выполнена в классическом стиле Веб 1.0, без CSS селекторов и id, самым надежным способом обратиться к интересующим меня кускам DOM будет именно xpath.
Стоит помнить, что xpath селектор, который можно скопировать в консоли браузера, будет содержать теги tbody, созданные уже движком. Я потратил некоторое время, выясняя почему lxml не видит нужные мне элементы.
Проверяем в консоли, что все работает.
p = load_page('http://www.sitecity.ru/userlist.phtml')
Посмотрим первые три ссылки пагинации:
[a.get('href') for a in get_pagination(p)[:3]]
| userlist.phtml?alpha=a&page=2 | userlist.phtml?alpha=a&page=3 | userlist.phtml?alpha=a&page=4 |
Индексы тоже получили
[a.get('href') for a in get_index(p)[:5]]
| userlist.phtml?alpha=b | userlist.phtml?alpha=c | userlist.phtml?alpha=d | userlist.phtml?alpha=e | userlist.phtml?alpha=f |
Теперь надо написать функцию получения, собственно, полезных данных и собрать все это воедино.
def get_links(tree):
rows = tree.xpath('/html/body/table/tr[2]/td[3]/table/tr[1]/td/table/tr[2]/td[2]/div[3]/table')[0]
def strip(row):
return (row[1][0].text,
row[1][0].attrib.get('href'),
str(row[2].text).strip(),
str(row[3].text).strip())
return tuple(map(strip, rows[1:]))
Функция возвращает кортеж исколючительно для удобства раскладывания этих результатов в БД. rows[1:] - потому что заголовок таблицы полезной нагрузки не содержит.
Сначала итерируем по индексам, внутри каждого индекса - по пагинации, на каждой странице собираем послезную нагрузку, парсим, кладем в БД.
def parse_page(page, cur, conn):
print('Parsing: [' + page + ']')
p = load_page('http://www.sitecity.ru/' + page)
links = get_links(p)
cur.executemany("INSERT INTO sc VALUES(?, ?, ?, ?);", links)
conn.commit()
return p
def parse_index(index, cur, conn):
print('Dropped into: [' + index + ']')
i = parse_page(index, cur, conn)
pages = get_pagination(i)
list(map(lambda p: parse_page(p, cur, conn), pages))
conn.commit()
def run():
conn = sqlite.connect('site-city.db')
cur = conn.cursor()
cur.execute("DROP TABLE IF EXISTS sc;")
cur.execute("CREATE TABLE sc(name TEXT, link TEXT, created_at TEXT, updated_at TEXT);")
# Start from main page
p = parse_page('userlist.phtml', cur, conn)
for page in get_pagination(p):
parse_page(page, cur, conn)
# Iterate through indexes
for index in get_indexes(p):
parse_index(index, cur, conn)
conn.close()
Оставляем базу наполняться. Время я не засекал, но по ощущениям потребовалось минуты две-три.
Подключимся к полученой базе клиентом:
sqlite3 site-city.db
погоняем данные в сортировке - это поможет быстро увидеть, есть ли у нас где-то пустые или лишние поля:
SELECT * FROM sc ORDER BY created_at DESC LIMIT 3;
SELECT * FROM sc ORDER BY name DESC LIMIT 3;
Выглядит валидно, можно подгружать это в аналитику. Сразу укажем pandas какие колонки стоит распарсить - в нашем случае это даты.
import pandas as pd
import sqlite3 as sqlite
conn = sqlite.connect('site-city.db')
cur = conn.cursor()
df = pd.read_sql_query("select * from sc;", conn, parse_dates={"created_at": "%Y-%m-%d", "updated_at": "%Y-%m-%d"})
Ну вот данные перед нами. Давайте посмотрим самые старые сайты ресурса:
df.sort_values(by='created_at', ascending=True).head(5)[['link', 'created_at']]
link created_at
41367 http://schastlivaya.sitecity.ru 2000-09-18
19542 http://hunta.sitecity.ru 2000-09-21
37046 http://polina-love.sitecity.ru 2000-09-21
17351 http://gleb.sitecity.ru 2000-09-21
46006 http://svarog.sitecity.ru 2000-09-21
Ух! Вот он, старейший сайт ресурса!
 Осторожно! В фотоальбомах присутствует контент, за который в 2019 году могут спросить.
Осторожно! В фотоальбомах присутствует контент, за который в 2019 году могут спросить.
Бот
Отлично, но “вручную” просматривать базу будет банально лень. Надо чтоб каждый сайт мне приносили на подносе. Что-то на подобии Narod.ru бота было бы отличным решением. Сказано-сделано. Получаю telegram bot token, пишу простенького бота. Лично мне не хватает в боте Народа скриншотов. Беглый взгляд на находку поможет отлечить зерна от откровенных плевел under construction. Хочешь-не хочешь, для создания скриншотов придется запускать как минимум движок браузера. Я выбираю PhantomJS - обертку над WebKit, просто потому что работал с ней ранее.
Кроме фотографии добываем <title> странички. Конструктор SiteCity позволял редактировать мета-теги страницы, в частности Description и Keywords. Из практики можно сказать, что немногие сайтостроители пользовались этой настройкой, но те, кто доходил до этого шага, иногда проявляли смекалу, потому добавляем и эти два тега в выдачу.
Весь код бота приводить не буду - это не тема даной статьи - приведу лишь конечный шаблон сообщений бота, FYI.
const caption = `
<code>Site #${Site.id}:</code> <a href="${Site.link}">${Site.title || Site.name.split('.')[0]}</a>
<code>Description:</code> ${Site.description}
<code>Keywords: </code> ${Site.keywords}
<code>Created: </code> ${Site.created_at}
<code>Upadted: </code> ${Site.updated_at}
<code>Link: </code> <a href="${Site.link}">${Site.link}</a>`
Присоединяйтесь, разбирайте, изучайте!
Небольшой дайджест годноты, собраной за первое время
- rikki-chedwik.sitecity.ru - тема - сериал H2O
- h2omermaids21.sitecity.ru - тот же сериал
- superataka.sitecity.ru - как ни странно, сайт посвящен певице Линде. По сравнению с сайтами сайтсити, этот достаточно наполненый
- erreway-ua.sitecity.ru - сайт посвящен группе Erreway, состоящей из звезд сериала “Мятежный путь” - последний является популярной тематикой для реурсов в этом сегменте
- byanka.sitecity.ru - Бьянка
- maksim-fan.sitecity.ru - МакSим
- pravda-o.sitecity.ru - “Полезные ссылки” - настоящий швейцарский нож. советую обратить внимание. Большая часть ссылок живые, ведут на забытые миром ресурсы с музыкой и фотографиями.
- lanfir.sitecity.ru - сайт девушки Ольги из Эстонии, путешествие и свадьба в Индии, истории про домашних любимцев. В наше время люди о таком пишет в фейсбук. Но разве есть в соц сетях эта теплота гифок-фонов, и самодельной верстки?
- pretty-style.sitecity.ru - редкий пример реального слива секретных данных
- nirma.sitecity.ru - сайт немецкой овчарки по имени Нирма Грин Глэди Прицер
- ank.sitecity.ru - “Скромный работник компьютерного отдела пивоваренного комбината им. Степана Разина (пиво FOREVER! :))”
- leaz.sitecity.ru - фотографии и полезные ссылки на тему Одессы. Фото старые, отсканированые, тоже душа.
- expedition1.sitecity.ru - “ПАРУСНАЯ ЭКПЕДИЦИЯ ВОКРУГ СВЕТА ЗА ЕДИНЕНИЕ ХРИСТИАН”. Ресурс увидел свет 18 мая 2006, что интересно, он до сих пор продолжает существовать но уже на современных площадках и немного изменив тему.
- http://malysh.sitecity.ru/ - страница Людмилы из Ванкувера. Много пленочных фото ее путешествий, друзей и мужа.
- http://bxms.sitecity.ru/ - Сайт группы, смешивающей электронный бит и сырый гитары черного металла. Весь альбом есть в ВК, рекомендую ознакомиться с творчеством. Одна новость “11.05.08. Басист MKD в связи с весенним призывом покидает группу” чего стоит!
Чего хотелось бы
Бот создавался в творческом порыве при обнаружении каталога и никакие надежды на него не возлагались. Код написаный на коленке запустился, заработал и за несколько дней показал что интересный контент на ресурсе имеется.
Посколько SiteCity является конструктором сайтов, а не полноценным хостингом, все его страницы и урлы имеют шаблонный вид. Например http://lovesex.sitecity.ru/album_1702150244.phtml. Это дает простор для автоматизации. При подготовке страницы на выдачу бот мог бы автоматически вычленять ссылки на потенциальные источники интересных находок - альбомы. То же самое касается страниц “Under construction”, коих на ресурсе оказалось немало.
На даном этапе уже приблизительно стали ясны очертания островка информации, которым является SiceCity. Хочется поднять вторичную базу, посерьезнее чем sqlite и собрать туда даные о страницах, а не только адреса. Банально мучает любопытство - какой из стандартных фонов странички достоверно является самым популярным в каталоге СайтСити и какой процент страниц ушел дальше чем “Сайт в разработке”.
SiteCity - слепок своего времени. Большинство живых сайтов отображает увлечения подростков того времени - Tokio Hotel, W.I.T.C.H., Totally Spies, H20, аниме, CS. Настоящий naïve web, больше так не делают. Конечно сразу возникает желание сберечь все буйство красок и запакованную в десятки киллобайт гифок, эпилепсию. Это технический и организационный вызов, но первые 10 гигабайт уже лежат архивом.
Рандомный сайт раз в 15 минут побуждает отвлечься от рутины и придаться философскому созерцанию искренней простоты. Некоторые странички привлекают внимание фотографиями, творчеством. Кое-где это чистый и забавный абсурд.
Пока наша команда трудилась над СайтСити из небытия и глубин времени всплыли другие статические хостинги и конструкторы сайтов из прошлого. Часть из них описана в первой части статьи, часть просто попадалась во время поиска. Все это уже история. Каждая отдельная страничка, возможно, и не представляет особой ценности. Но архив всего ресурса в целом ценен как артефакт. Отвлекаясь от парсинга СайтСити мы обсуждали гипотетическую архитектуру системы архивирования и ре-хостинга подобных вещей. Было бы здорово собрать “под одной крышей” все крупные статические хостинги, проиндексировать их вдоль и поперек. Надеюсь, продолжение у этой истории все же будет.
От редактора
Если есть желание разбирать сайты “веб 1.0” в приятной компании, предлагаю присоединится к чату “Мусорщики Web 1.0”
© 2020 netwhood.online ― Сайт построен на Jekyll и Textlog theme